DNA And The Central Dogma: Gene Transcription And Translation
Article Sections
Overview
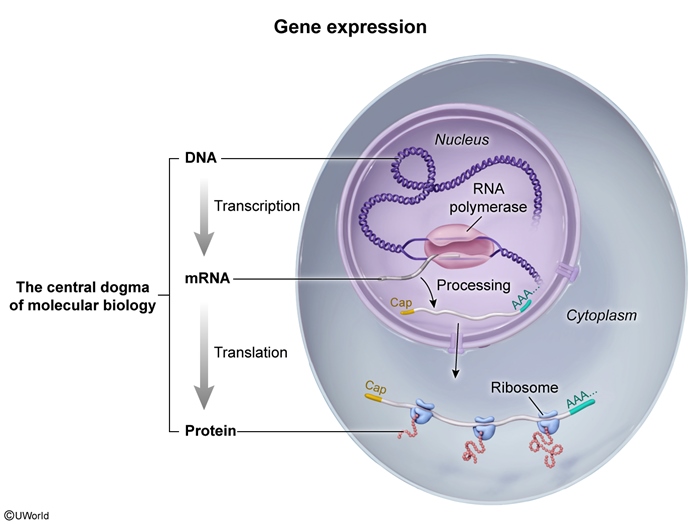
Deoxyribonucleic acid (DNA), which consists of strands of nucleotides with purine or pyrimidine nitrogenous bases, allows for the transmission of genetic information from one generation to another. The expression of the information encoded in DNA is mediated by ribonucleic acid (RNA). The central dogma of molecular biology describes the flow of genetic information from DNA to RNA to protein (Figure 1). This directional process underlies gene expression and involves 2 major stages: transcription (from DNA to RNA) and translation (from RNA to protein). Unlike in prokaryotes (which generally do not have membrane-bound organelles), these processes are compartmentalized in eukaryotes, with transcription occurring in the nucleus and translation occurring in the cytoplasm.
DNA structure and replication
DNA consists of 2 strands of nucleotides that run in opposite directions (antiparallel) and twist around each other to form a right-handed double helix. Each DNA strand is a polymer of deoxyribonucleotides, which are composed of deoxyribose sugar, a phosphate group, and a nitrogenous base (adenine [A], guanine [G], cytosine [C], or thymine [T]). Nitrogenous bases are either purines (A and G; containing 2 rings) or pyrimidines (C and T; containing 1 ring). Complementary base pairing occurs between the nitrogenous bases of opposite strands: A pairs with T, and G pairs with C. RNA is similar in structure to DNA but contains ribose sugar (instead of deoxyribose sugar) and uracil (U) (instead of T).
In each nucleotide, the carbons of the sugar are numbered 1′ through 5′; the 5′ carbon is attached to a phosphate group, and the 3′ carbon carries a hydroxyl (OH) group. This orientation (ie, a 5′ end with a free phosphate group and a 3′ end with a free OH group) defines the direction of a nucleic acid strand. Linkage of nucleotides is the basis for both DNA synthesis (replication) and RNA synthesis (transcription). During these processes, nucleotides are added to the 3′ OH group, resulting in strand elongation in the 5′ → 3′ direction.
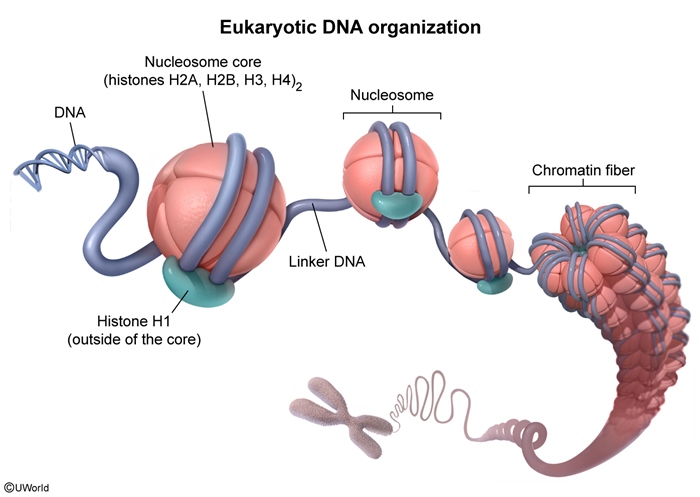
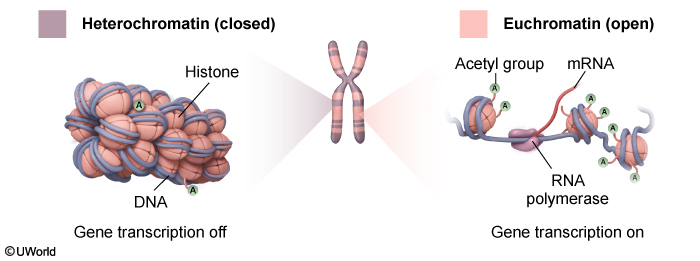
Chromatin structure and regulationDNA wraps around histone octamers (which are made up of 2 copies each of H2A, H2B, H3, and H4) to form nucleosomes. Nucleosomes are separated by a stretch of DNA, or linker DNA, giving them the appearance of beads on a string (Figure 2). DNA in this loose structure (euchromatin) is about 10 nm in diameter and provides a high degree of transcriptional access. The degree of compaction changes based on epigenetic modification (eg, histone acetylation) and binding of additional DNA structural proteins (Figure 3). One such protein is histone H1, which, in contrast to the other histone proteins, is located outside the nucleosome core. Histone H1 binds to both the nucleosome and adjacent linker DNA, which facilitates packaging of chromatin into a thicker (30 nm), more compact structure (heterochromatin) that limits transcriptional access to the DNA. During cell division, chromatin interacts with additional proteins (eg, nuclear scaffold proteins) and undergoes further coiling, ultimately forming condensed chromosomes.
DNA replicationFor a copy of genetic information to be passed to daughter cells during cell division, DNA must first be copied (replicated). This process takes place during the S phase of the cell cycle. DNA replication is semiconservative, which means that each new (daughter) strand is synthesized using one of the original (parent or parental) strands as a template. Replication initiates at origins of replication, which are specialized nucleotide sequences that bind replication machinery.
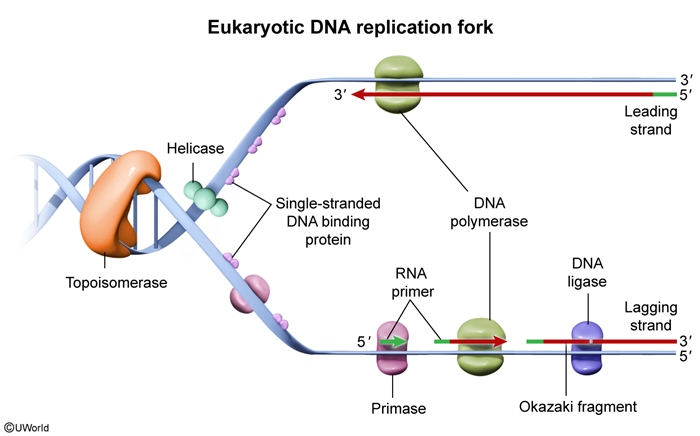
Key steps of DNA replication include the following (Figure 4):
- Helicase unwinds DNA, creating a replication fork.
- Single-stranded DNA–binding proteins (SSBPs) prevent reannealing (ie, they hold the 2 DNA strands apart).
- Topoisomerase relieves DNA supercoiling (overwinding) ahead of the replication fork.
- Primase synthesizes RNA primers that provide a free 3′ OH group for DNA polymerase to begin DNA synthesis.
- DNA polymerase III (in prokaryotes) or DNA polymerase δ/ε (in eukaryotes) extends DNA from RNA primers by attaching uncoupled deoxynucleotide triphosphates (composed of a nitrogenous base [A, G, C, T] with 3 phosphate groups) to the growing DNA strand, with the 3′ OH from the last nucleotide of the growing strand "attacking" the 5′ phosphate group of the incoming deoxynucleotide triphosphate.
- DNA polymerase I (prokaryotes) or RNase H and polymerase δ (eukaryotes) replace RNA primers with DNA.
Because all DNA polymerases can synthesize DNA only in the 5′ → 3′ direction, one daughter strand (the leading strand) is synthesized continuously toward the replication fork. The other strand (the lagging strand) must be synthesized discontinuously in a direction away from the replication fork, with new segments being added as more DNA is unwound. Because of this discontinuity, replication of the lagging strand requires repeated priming and synthesis of short Okazaki fragments, which are subsequently ligated by DNA ligase.
Differences between prokaryotic and eukaryotic replication- Prokaryotes (eg, bacteria) have circular DNA with a single origin of replication; eukaryotes have linear DNA with multiple origins of replication.
- Prokaryotes possess 3 major DNA polymerases (I, II, III), whereas eukaryotes have 5 major DNA polymerases (α, β, γ, δ, ε).
- DNA replication is slower in eukaryotes than in prokaryotes.
Because DNA polymerases require a free 3′ OH group, the ends of linear chromosomes cannot be fully replicated, resulting in progressive shortening with each round of replication. Telomeres, composed of hundreds of tandem TTAGGG repeats at the end of the chromosome, protect coding sequences. In germ cells, stem cells, and some cancer cells, telomerase, a reverse transcriptase, replenishes telomere sequences, maintaining replicative capacity.
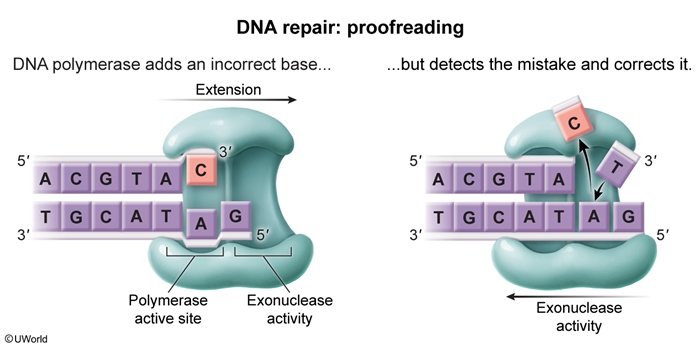
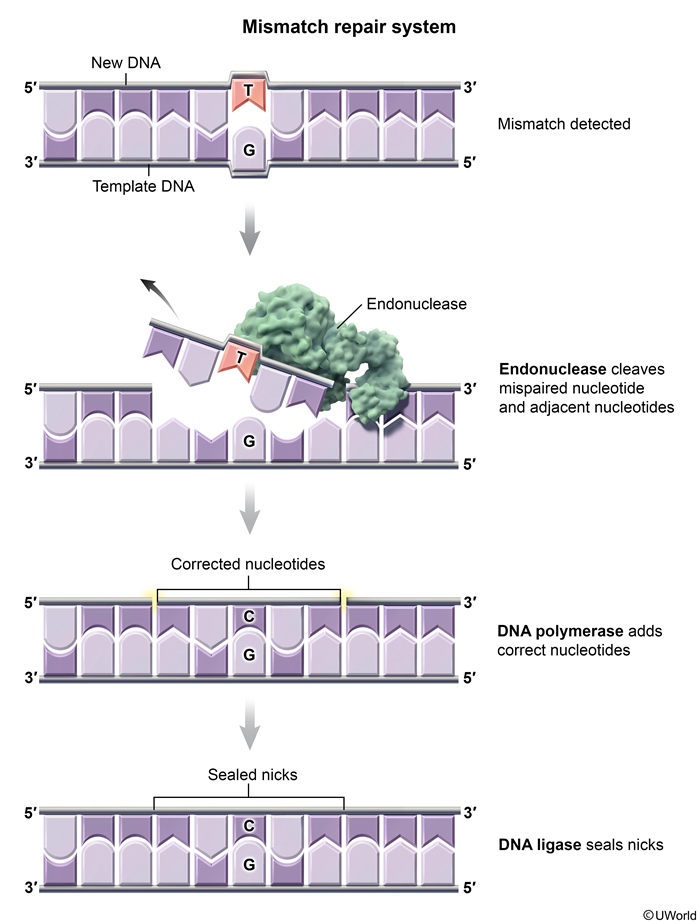
DNA repair mechanisms- During replication, DNA polymerase III (prokaryotes) and DNA polymerase δ/ε (eukaryotes) perform 3′ → 5′ exonucleolytic proofreading if incorrect nucleotide pairing occurs (Figure 5). Immediately after replication, the DNA mismatch repair (MMR) system is activated when a base mismatch is identified. MMR enzymes recognize mismatches, excise a stretch of the daughter strand (identified via methylation status in prokaryotes and strand breaks in eukaryotes), and fill in the gap. These enzymes have endonuclease (rather than exonuclease) activity because the mismatched nucleotides must be excised from within an existing DNA strand (Figure 6).
- Although DNA mismatches can occur during replication, they can also develop spontaneously or following exposure to harmful conditions (eg, ultraviolet [UV]) light). Base excision repair removes small, nonbulky lesions (eg, deamination, oxidation) (Figure 7). Nucleotide excision repair removes bulky lesions (eg, UV-induced thymine dimers). Both processes involve lesion recognition, excision, gap-filling by DNA polymerase, and ligation.
- In case of a double-stranded break, homologous recombination uses a sister chromatid as a template for high-fidelity repair. In contrast, nonhomologous end joining directly ligates DNA ends without a template, occasionally introducing mutations (Figure 8).
Transcription and RNA processing
Transcription is the process by which the genetic information encoded in DNA is copied into a complementary RNA sequence by RNA polymerase. There are 3 stages of transcription (Figure 9):
- Initiation.
- Elongation.
- Termination.
Most DNA is noncoding (introns); therefore, boundaries exist that define where coding regions (exons) begin and end. These boundaries are marked by nucleotide sequences called promoters and terminators.
Transcription initiation requires the recognition of promoter sequences (Figure 10):
- TATA box: Located approximately 25 bases upstream of the transcription start site.
- CAAT box: Located approximately 75 bases upstream of the transcription start site.
RNA polymerase II binds the promoter with the help of general transcription factors to form the transcription initiation complex (Figure 11). Activator proteins can bind enhancer sequences and interact with the transcription complex to enhance transcription (Figure 12).
Transcription is similar to DNA replication in that RNA polymerase II assembles nucleotides in the 5′ → 3′ direction; however, unlike the DNA polymerases used in DNA replication, RNA polymerase does not need an RNA primer to begin assembling nucleotides.
ElongationWhen the transcription machinery is assembled at the promoter, RNA polymerase II unwinds the DNA helix and transcription begins at the transcription start site (Figure 13). One DNA strand is known as the coding (sense) strand (5′ → 3′), and the other is the noncoding/template (antisense) strand (3′ → 5′). Only the noncoding/template (antisense) strand of DNA is transcribed into RNA.
TerminationTermination occurs when the RNA polymerase encounters a polyadenylation signal sequence (5′-AAUAAA-3′) in the RNA transcript, leading to cleavage of the nascent transcript and release from the polymerase.
RNA processingIn prokaryotes, the messenger RNA (mRNA) transcript that detaches from the DNA is available for translation to protein with no further modification. In contrast, eukaryotic primary transcripts (heterogeneous nuclear RNA [hnRNA]) must undergo the following modifications before translation:
- 5′ capping: Capping involves the addition of 7-methylguanosine (m⁷G) via a 5′-5′ triphosphate linkage to protect RNA from degradation and facilitate ribosome binding during translation (detailed below).
- Polyadenylation: A poly(A) tail is added to the 3′ end downstream of the polyadenylation signal by poly-A polymerase to stabilize mRNA and assist nuclear export.
- Splicing: The majority of DNA in eukaryotes is noncoding, and DNA sequences that code for a particular protein (exons) may be interrupted by noncoding regions (introns). Splicing involves the removal of noncoding introns and the joining of coding exons. It is carried out by the spliceosome, a complex composed of small nuclear ribonucleoproteins (snRNPs) and small nuclear RNA (snRNA) (Figure 14). The spliceosome recognizes splice donor sites (5′ end of introns) and splice acceptor sites (3′ end of introns). With alternative splicing, exons and introns can be removed in a differential manner. Therefore, multiple distinct mRNA transcripts and protein isoforms can be generated from a single gene (Figure 15).
After export to the cytoplasm, mature mRNA may either engage in translation by ribosomes (described next) or be sequestered in P bodies, where it can be stored, degraded, or regulated via RNA exonucleases and decapping enzymes.
Translation
Translation is the process by which mRNA is decoded into a specific sequence of amino acids to form a polypeptide chain. It links the nucleotide-based language of RNA to the amino acid–based structure of proteins. There are 20 types of amino acids in proteins and only 4 types of nucleotides (A, C, U, G) in mRNA, so the genetic code helps translate combinations of 3 nucleotides (called codons) into amino acids (Table 1).
The small ribosomal subunit (30S in prokaryotes, 40S in eukaryotes) binds both mRNA, which contains genetic information that serves as a reading frame, and transfer RNA (tRNA), which serves as an amino acid carrier. The large ribosomal subunit (50S in prokaryotes, 60S in eukaryotes) contains peptidyltransferase, which catalyzes the formation of peptide bonds between amino acids to generate proteins.
Each codon in mRNA serves as a reading frame triplet that is translated into one amino acid based on the genetic code. There are 64 codons; 61 of them code for amino acids, and 3 (UAG, UGA, and UAA) serve as termination signals. AUG, which codes for methionine, is the start signal codon that initiates translation.
As with transcription, there are 3 stages to translation:
- Initiation.
- Elongation.
- Termination.
Translation occurs in the cytoplasm (Figure 16). Eukaryotic translation initiation requires the assembly of the following (Figure 17):
- Ribosomal subunits (60S and 40S, resulting in an 80S ribosomal unit).
- mRNA.
- Initiation factors.
- Initiator tRNA (carrying methionine).
- Guanosine-5′-triphosphate.
The small ribosomal subunit (40S) initially binds to the 5′ cap of mRNA and scans for the AUG start codon, which is positioned near the beginning of the mRNA and is surrounded by the Kozak consensus sequence. This short sequence identifies the specific AUG codon that serves as the initiator of translation.
It is analogous to the Shine-Dalgarno mRNA sequence in prokaryotes, which is located upstream from the initiation codon AUG and recognizes a tRNA carrying N-formylmethionine. This sequence allows binding of the 30S ribosomal subunit to mRNA and this N-formylmethionine-tRNA to form the prokaryotic 30S initiation complex. The energy for this reaction brings the 50S subunit into the initiation complex, resulting in a 70S ribosomal unit.
ElongationDuring elongation, the ribosome repeats the following sequence (Figure 18):
- tRNAs deliver amino acids.
- Peptide bonds form between amino acids via the ribosome's peptidyl transferase activity.
Normally, in a process catalyzed by aminoacyl-tRNA synthetases (AA-tRNA synthetases), the 3′ end of each tRNA is covalently attached to a specific amino acid (Figure 19), with each amino acid/tRNA pair having a specific AA-tRNA synthetase that links them. tRNA recognizes the 3-base codon on the mRNA being translated through the complementary bases in the tRNA anticodon region. A charged tRNA (ie, tRNA covalently attached to an amino acid) enters the A (aminoacyl) site of the ribosome, and the tRNA anticodon binds to the corresponding mRNA codon. A peptide bond forms between the newly added amino acid and the polypeptide strand, and the peptidyl-tRNA moves to the P (peptidyl) site as the ribosome translocates to the next codon. The used tRNA moves to the E (exit) site and leaves. This cycle extends the polypeptide chain (N-terminus → C-terminus of the polypeptide chain (Figure 20)).
The cloverleaf-like secondary structure of tRNA contains the following regions that facilitate this process (Figure 21):
- The acceptor stem is created through the base pairing of 5′-terminal nucleotides with 3′-terminal nucleotides. The CCA tail hangs off the 3′ end, with the amino acid bound to the 3′ terminal hydroxyl group. tRNA is "loaded" with the appropriate amino acid by AA-tRNA synthetase. A 3′ CCA tail is added to the 3′ end of tRNA as a posttranscriptional modification in eukaryotes and most prokaryotes. Several enzymes use this tail to help recognize tRNA molecules.
- The D loop contains numerous dihydrouridine residues, which are modified bases often present in tRNA. The D loop (along with the acceptor stem and anticodon loop) facilitates correct tRNA recognition by the proper aminoacyl tRNA synthetase.
- The anticodon loop contains sequences that are complementary to the mRNA codon. During translation, the ribosome complex selects the proper tRNA based on its anticodon sequence.
- The T loop contains the TΨC sequence (ribothymidine, pseudouridine, and cytidine residues) that is necessary for binding of tRNA to ribosomes.
When a stop codon (UAA, UAG, or UGA) enters the A site of the ribosome, it is not recognized by a charged tRNA because it does not code for an amino acid. Instead, the stop codon is recognized by releasing factor proteins, which bind the stop codon and hydrolyze the bond between the polypeptide chain and the tRNA in the P site. The newly formed polypeptide chain is then released, and the ribosome-mRNA complex disassembles (Figure 22).
Posttranslational processingProteins undergo folding, chemical modifications (eg, phosphorylation, glycosylation), and trafficking to functional destinations.
Summary
The flow of genetic information from DNA to RNA to protein is known as the central dogma of molecular biology. DNA and RNA are linear polymers of nucleotides, each consisting of a sugar, phosphate group, and nitrogenous base. Transcription (DNA to RNA) proceeds in 3 phases: RNA polymerase II and general transcription factors initiate transcription at promoter elements, elongate the RNA strand in the 5′ → 3′ direction along the template, and terminate transcription after a polyadenylation signal. Translation (RNA to protein), likewise, has 3 stages: initiation, elongation, and termination. The AUG codon (which codes for methionine) serves as a start codon; elongation cycles drive aminoacyl-tRNAs through ribosomal A, P, and E sites as peptidyltransferase forms peptide bonds; and a stop codon recruits release factors that hydrolyze the peptidyl-tRNA bond, freeing the completed polypeptide.
Continue Learning with UWorld
Get the full DNA And The Central Dogma: Gene Transcription And Translation article plus rich visuals, real-world cases, and in-depth insights from medical experts, all available through the UWorld Medical Library.
Figures